0
SitePuller
基于Web的网站下载程序,可在线下载所有网站文件。它会抓取并生成任何站点(包括所有图像)的所有html,css,js代码的zip文件。粘贴网站链接,它将为您克隆。SitePuller提供了一种干净方便的方式来下载所有网站文件。我们关注任何网站目录中的每个html,css,js和图片文件。我们的Python驱动的后端可以轻松获取被日趋复杂的代码结构隐藏的文件。这些是我们可以解码的一些复杂的网站代码,只要有互联网连接即可,要免费下载网站,您需要一个网站链接,链接/网址应以http://或htps://开头,粘贴您的网页的URL。要在本节的下载表单中下载,然后单击下载。所有的html文件,css,js,图像和图标都将由我们的网站开膛手自动下载。要下载网站模板,请访问您要从中下载模板的网站,单击预览,以便您可以获取网站模板的实际Web模板URL,并将其粘贴到下载部分中,以继续进行网站下载。您将可以获取带有CSS的专业网站模板免费下载html。我们的用户可以免费获取css / js / bootstrap网站模板。这些是已下载的主要模板,1.公司网站模板免费下载css html 2.响应网站模板免费下载css3 html5 3.在线购物网站模板免费下载css html5 4. css5免费下载html5模板。html5 css3模板6.响应式模板html5 css3 7. html5 css3模板
sitepuller
分类目录
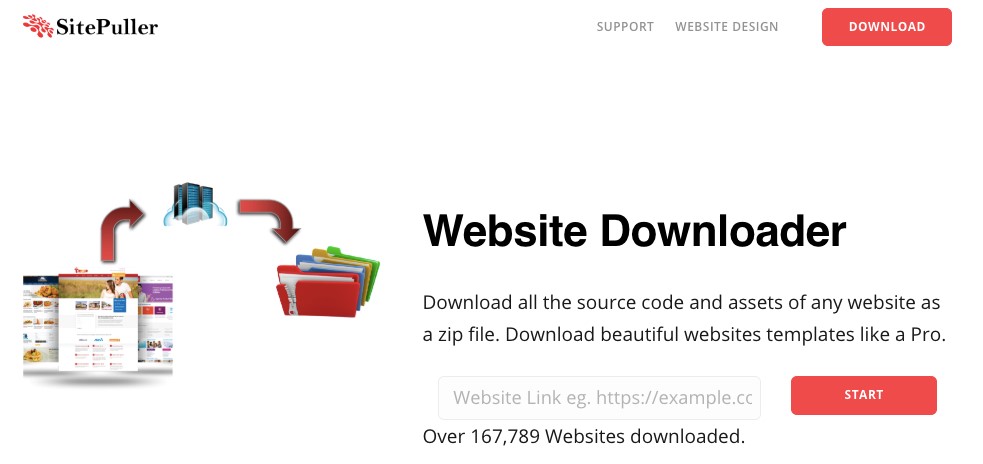
Mac版SitePuller的替代品
85
17
SiteSucker
macOS应用程序,可从Internet自动下载网站。它通过将站点的网页,图像,PDF,样式表和其他文件异步复制到本地硬盘驱动器,从而复制站点的目录结构来实现此目的。
14
PageArchiver
PageArchiver(以前称为“ SingleFile剪贴簿”)是一个Chrome扩展程序,可帮助您存档网页以供离线阅读。主要功能包括:
14
7
WebScrapBook
浏览器扩展程序,可高度自定义地忠实捕获网页。
1